Professor Zhou Ligong's years of hard work on the books "Programming and Data Structure" and "Programming for AMetal Framework and Interface (I)" sparked a learning trend in the electronics industry. With Professor Zhou's authorization, this public account has serialized the content of the book "Programming and Data Structure," aiming to share it with others.
The third chapter is about algorithms and data structures. This section focuses on the separation of stored values and addresses in 3.2.1 of the unidirectional linked list, as well as the data and p_next in 3.2.2.
>> 3.2.1 Stored Value and Address
1. Stored Value
In a structure, although the "current structure type" cannot be used as the type of the structure member, the "pointer to the current structure type" can be used as the type of the structure member. For example:

Here, slist stands for single list, indicating that the node is a singly linked list node. Since the AMetal platform requires all letters to be lowercase for type names, variable names, and function names, and macros must use uppercase letters, the type names are also kept in lowercase to maintain consistency with the platform.
Since p_next is a pointer type rather than a struct, it points to the same type of struct variable. The compiler knows the length of the pointer before determining the length of the structure, making this self-referencing valid. p_next is both a member of the struct _slist_node type and points to the struct _slist_node type of data. Then, the type name slist_node_t is defined for this structure:

AMetal specifies that new type names defined using typedef should end with "_t", so subsequent type names follow this rule. However, one must be cautious of the following declaration traps:

When declaring the p_next pointer, the typedef has not been completed yet, so slist_node_t is not available, leading to a compiler error. Alternatively, you can use typedef before defining the structure, allowing the use of slist_node_t when declaring the p_next pointer:

Finally, it can also be defined in a combined manner, as shown below:

This method is often used for lists, trees, and other dynamic data structures. p_next is called a link, and each structure connects to the next by p_next, as shown in Figure 3.1. The data stores the node's data, provided by the caller (application), while p_next stores the address pointing to the next node in the linked list. The arrow indicates the chain, and the value of p_next is the address of the next node. When p_next is NULL (0), it means the linked list has ended. Thus, a linked list can be thought of as a series of connected elements, where the links ensure all elements are accessible. If a link is lost, all elements from that point onward become inaccessible.

Figure 3.1 Schematic diagram of the linked list
It is usually necessary to define a pointer p_head pointing to the head node to facilitate sequential access to all nodes starting from the head. For example:
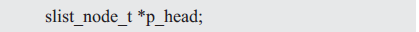
After adding the head node p_head, the complete linked list is shown in Figure 3.2.

Figure 3.2 Add a pointer to the node header
Once the value of p_head is obtained, all nodes of the linked list can be traversed in order. For example:

For functions that operate on linked lists, tests must be performed to ensure that operations on an empty list are also correct. If p_head is used directly to access each node, once traversal is complete, the value of p_head becomes NULL, no longer pointing to the first node, thus losing the entire list. Therefore, it is necessary to access each node through a temporary pointer variable. For example:

Next, consider adding nodes to the end of the list. In the initial state, the linked list is empty, with no nodes. At this time, p_head is NULL, and the newly added node becomes the head node, with the value of p_head modified to point to the new node. The change in the linked list is shown in Figure 3.3.
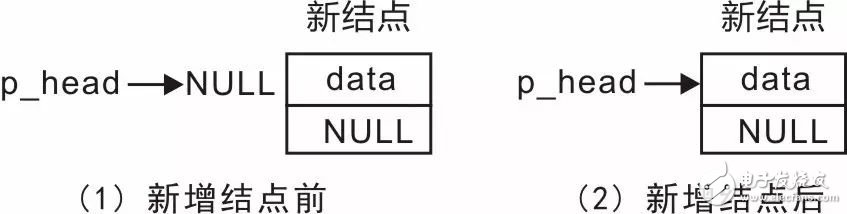
Figure 3.3 Adding a node when the linked list is empty
Since the new node is added at the end of the list, the value of p_next in the new node is NULL, as shown in Listing 3.6.
Listing 3.6 Add Node Sample Program (chain table is empty)

Now, let's write a simple example to verify that the node is added successfully, as shown in Listing 3.7.
Listing 3.7 Add Node Sample Program (1)

If the node is successfully added, the data 1 can be printed out by printf. Unfortunately, after running the program, nothing happened. When the linked list is empty, the core job of adding a node is to "modify the value of p_head from NULL to a pointer to the new node." Has p_head been modified since slist_add_tail() was called?
When a pointer is passed to a function, it passes the value. If you want to modify the original pointer instead of a copy, you need to pass a pointer to the pointer. p_head is defined in the main program, and only the NULL value is passed as an argument to the formal parameter of slist_add_tail(). Since then, p_head has no association with slist_add_tail(), so slist_add_tail() cannot modify p_head at all. To modify p_head at the time of the call, the address of the pointer must be passed to slist_add_tail(), as described in Listing 3.8.
Listing 3.8 Sample program for adding a new node when the linked list is empty

The test program shown in Listing 3.9 can verify that the addition of the node is successful. First, initialize the linked list to empty, then pass the address of p_head, and then start from the head node and access each node in turn.
Listing 3.9 Adding a Node Sample Program (2)

When the linked list is not empty, assume there is already a node with the value of data1, and then a node with the value of data2 is added. The change in the linked list is shown in Figure 3.4.
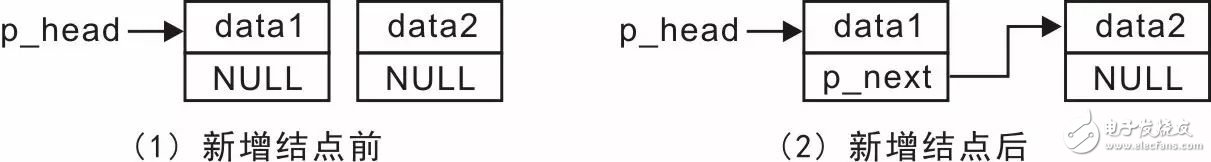
Figure 3.4 Adding a node when the linked list is not empty
The implementation process only needs to modify the value of the original end-of-spin node p_next to change it from a NULL pointer to a pointer to the new node. See Listing 3.10 for details.
Listing 3.10 New Node Sample Program

It is now possible to add more nodes as a test program based on Listing 3.9, as detailed in Listing 3.11.
Listing 3.11 Add Node Sample Program (3)

Through this program, you can verify that the node is added successfully, but you can see that the program list 3.10 can be found. When adding a node, you need to determine whether the current linked list is empty, and then make corresponding processing according to the actual situation. The reason for the conditional judgment is that the linked list may be empty and there is no valid node. If the linked list initially has a node head:

Since this is an actual node, it is no longer a pointer to the head node, so the linked list cannot be empty. The schematic diagram of the linked list is shown in Figure 3.5.

Figure 3.5 Schematic diagram of the linked list
For this type of linked list, there is always a head node that does not require valid data. For an empty linked list, it contains at least the head node. The schematic diagram of the empty linked list is shown in Figure 3.6. Since no other nodes are included in the initialization, the value of p_next is NULL.
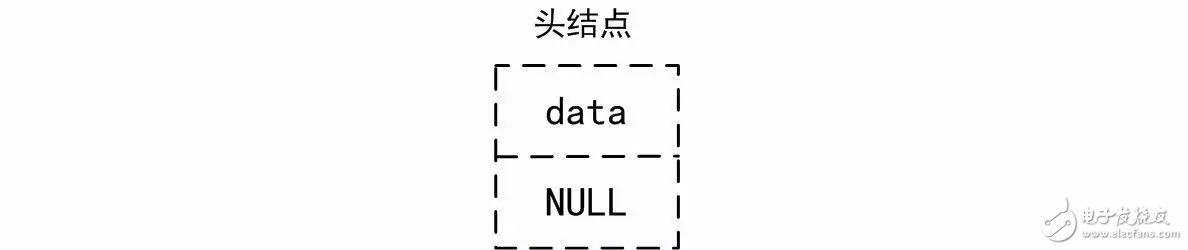
Figure 3.6 Schematic diagram of the empty linked list
When you need to add a new node, look for the tail node from the head node. When the tail node is found, the p_next value of the tail node is modified to change from a NULL pointer to a pointer to the new node, as shown in Listing 3.12.
Listing 3.12 New Node Sample Program

Note that p_head here always points to the existing head node, which is different from p_head in Listing 3.6. It can be tested using the test program shown in Listing 3.13. Since there is no successor node during initialization, the p_next field The value is NULL.
Listing 3.13 Add Node Sample Program (4)

Although the program shown in Listing 3.12 no longer uses the judgment statement, it brings a new problem. The data of the head node is idle, and only p_next is used, which is bound to waste memory. Of course, for the current example, data is int type data, occupying only 4 bytes, and wasting 4 bytes may be acceptable, if data is other types?
If the elements of the linked list are data in the student record, the structure is the best choice because the data in the student record is different types of data. As a sample program, it is not possible to cover everything, so only a few typical data is taken as a member of the structure. Based on this, a structure type and a new structure type name are specifically defined for the data in the student record. Its data type is defined as follows:

That is, the structure can be used to store the data in the student record, and the storage relationship of its members in memory is shown in Figure 3.7. If the element_type_t declaration is of the same type as student_t, the linked list data structure is:


Figure 3.7
That is, the type of data related to the application is another structure type student_t.
At this point, as long as you define a variable node of type slist_node_t, you can reference the members of the structure:

Then the storage relationship of each member of the linked list in memory is determined, as shown in Figure 3.8. If using an expression:

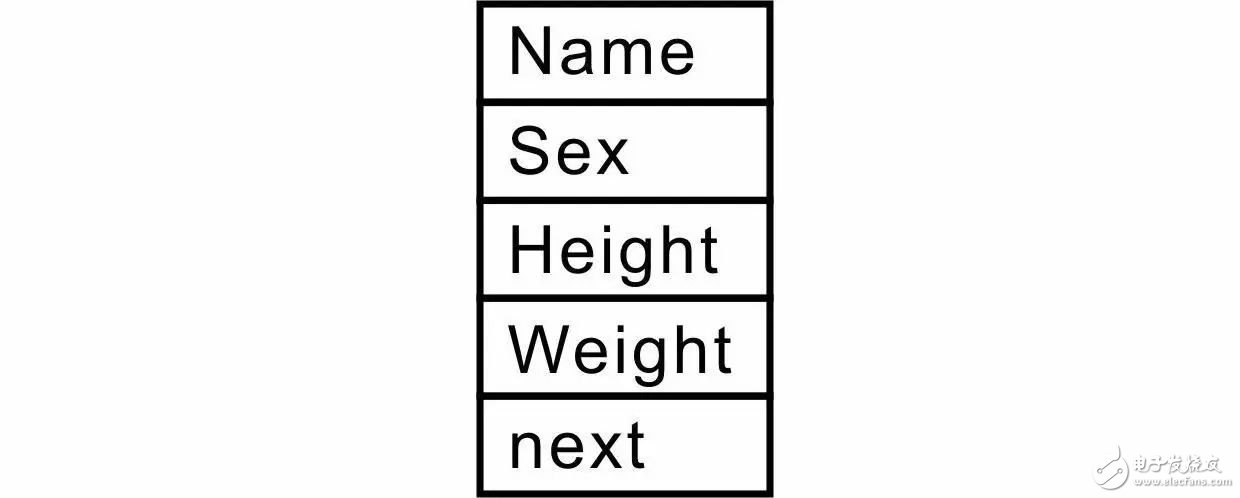
Figure 3.8
The member data of the slist_node_t structure can be referenced through the node variable. At this point, just use node.data as a student_t type variable, you can use the expression:

References the member name of the student_t structure member data (data in the student record).
When the data in the linked list changes from int type to student_t, the wasted space will be the size of the student_t type. Here is just an example. The student record may contain more information, such as student number, grade, blood type, dormitory number, etc., and the head node will waste more space.
At the same time, there is also a problem here. The change of the data type will lead to the change of the program behavior, making the program unable to be universal. The data type must be determined before compilation, and the program cannot be released in the form of a general library. If you want to make the code generic, use void * that accepts any data type.
2, Storage Address
In order to store the void * type elements in the linked list, you can use the linked list to store any pointer type data passed by the user. The data structure of the linked list node is defined as follows:

The data field type of the node is void * type pointer, data points to user data, and the data in the node is user data provided by the caller (application).
Although void * seems to be a pointer, it is essentially an integer, because in most compilers the pointer is the same size as the int, so the universal list is a linked list of the int data type. Only the data field of the node stores the address of the user data associated with the application.
Assuming that the data stored in the student record of the struct _student structure is user data, it is sufficient to pass the address of the structure variable storing the student record to the data field of the linked list node, that is, the structure of p->data pointing to the user data. Storage space, as shown in Figure 3.9. If the void * pointer points to a structure or a string, but a simple type such as an int, then just cast it at the time of use.
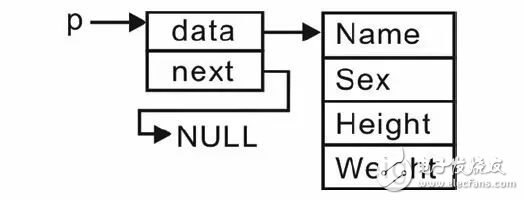
Figure 3.9 data points to user data
If you want to associate the linked list data with the student record structure, you must first define a student record and then point the void * pointer in the linked list node to the student record. Each node consumes more space for a void * pointer than a linked list of data members that directly use the student structure as a linked list node. Although there is not much space for a node, if there are many nodes, the wasted memory is quite considerable, especially in embedded systems where the memory resources themselves are very tight.
Obviously, to save memory space, you can't define void * type pointers. You must put data (such as student records) and p_next of linked list nodes together, but you can't reuse the linked list program.
Analysis of the definition of the current linked list node, which mainly consists of two parts: the p_next pointer of the linked list and the data data of the user's concern. Looking back at the slist_add_tail() function shown in Listing 3.12, there is no code to access data, indicating that data is independent of the linked list. In this case, can you separate them?
>> >> >> 3.2.2 Data is separated from p_next
Since the linked list only cares about the p_next pointer, there is no need to define the data field in the linked list node, so it is only necessary to keep the p_next pointer. The data structure of the linked list node (slist.h) is defined as follows:

Since there is no data in the node, the memory space is saved, and the schematic diagram is shown in Figure 3.10.

Figure 3.10 Schematic diagram of the linked list
When users need to use linked lists to manage data, they only need to associate data with linked list nodes. The easiest way is to package the data and linked list nodes together. Take the int type data as an example. First, the linked list node is used as a member of it, and then the int type data related to the user is added. The structure is defined as follows:

Thus, no matter what the data, the linked list node is only a member of the user data record. When calling the linked list interface, you only need to use the address of the node as the linked list interface parameter. When defining the data structure of the linked list node, since only the data member is deleted, the original slist_add_tail() function can be used directly. The sample program for managing int data is detailed in Listing 3.14.
Listing 3.14 Sample program for managing int data

Since the user needs to initialize the head to NULL, and the traversal needs to operate the p_next pointer of each node. The purpose of separating the data from p_next is to separate the respective functional responsibilities. The linked list only needs to be concerned with the processing of p_next, and the user only cares about the processing of the data. Therefore, for the user, the definition of the linked list node is a "black box," which can only access the linked list through the interface provided by the linked list, and should not access the specific members of the linked list node.
In order to complete the initial assignment of the head node, an initialization function should be provided, which essentially sets the p_next member in the head node to NULL. The prototype of the linked list initialization function is:

Since the type of the head node is the same as the type of other common nodes, it is easy for the user to think that this is a function to initialize all the nodes. In fact, the meaning of the head node is different from that of the ordinary node. Since the head node can be traversed through the entire linked list, the head node is often held by the owner of the linked list, while the ordinary node only represents a single node. a node. In order to avoid the user confusing the head node with other nodes, you need to define a header node type (slist.h):

Based on this, modify the linked list initialization function prototype (slist.h) to:

Among them, p_head points to the link header node to be initialized, and the implementation of the slist_init() function is shown in Listing 3.15.
Listing 3.15 List initialization function

Before adding a node to the linked list, you need to initialize the head node. which is:

Since the type of the head node is redefined, the function prototype that adds the node should also be modified accordingly. which is:

Among them, p_head points to the link header node, p_node is the new node, and the implementation of the slist_add_tail() function is shown in Listing 3.16.
Listing 3.16 New Node Sample Program

Similarly, the traversal of the current linked list is also a way to directly access the members of the node. The core code is as follows:
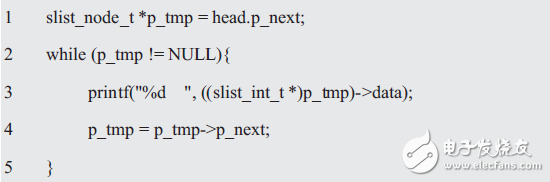
Here mainly three operations on the linked list: (1) get the first user node; (2) get the next node of the current node; (3) determine whether the linked list ends, compared with the end tag (NULL).
Based on this, three corresponding interfaces will be provided to implement these functions, so as to avoid direct access to node members. Their function prototype is (slist.h):

The implementation code is detailed in Listing 3.17.
Listing 3.17 traversing the relevant function implementation

The first user node obtained in the program is essentially the next node of the head node, so it can be called directly by calling slist_next_get(). Although slist_next_get() does not use the p_head parameter when it is implemented, the p_head parameter is passed in, because the p_head parameter will be used to implement other functions, for example, to determine if p_pos is in the linked list. Once you have these interface functions, you can complete the traversal, as shown in Listing 3.18.
Listing 3.18 Example program for implementing traversal using various interface functions

Thus, the return value of slist_begin_get() and slist_end_get() determines the range of the currently valid node, which is a semi-open and semi-closed space, namely: [begin, end), including begin, but does not include end. When begin and end are equal, it indicates that the current linked list is empty and there is no valid node.
In the traversal program shown in Listing 3.18, only the printf() statement is the statement that the user actually cares about. Other statements are fixed patterns. For this purpose, a general traversal function can be encapsulated, which is convenient for the user to process and link each link. Point the associated data. Obviously, only the user who uses the linked list knows the specific meaning of the data. The actual processing of the data should be done by the user. For example, the print statement in Listing 3.18, so the behavior of accessing the data should be defined by the user, defining a callback function. Passing parameters to the traversal function, each time a node is traversed, the callback function is called to process the data. The function prototype (slist.h) that traverses the linked list is:

Among them, p_head points to the link header node, and pfn_node_process is the node handle callback function. Each time a node is traversed, the function pointed to by pfn_node_process is called, which is convenient for the user to process the node data as needed. When the callback function is called, the user parameter p_arg is automatically used as the first parameter of the callback function, and the pointer to the node currently traversed is used as the second parameter of the callback function.
When traversing to a node, the user may wish to terminate the traversal, as long as a negative value is returned in the callback function. In general, to continue traversing, return 0 after the execution of the function. The implementation of the slist_foreach() function is detailed in Listing 3.19.
Listing 3.19 Traversing the linked list sample program

You can now use these interface functions to iterate through the functions shown in Listing 3.14, as detailed in Listing 3.20.
Listing 3.20 Sample program for managing int data
1.0Mm Pin Header Connector,1.27Mm Pin Header Connector,2.0Mm Pin Header Connector,2.54Mm Pin Header Connector
Dongguan City Yuanyue Electronics Co.Ltd , https://www.yyeconn.com