The traditional application area of ​​synchronous SRAM is the search engine, which is used to implement algorithms. For a long time, this was the main role SRAM played in the network. However, with the emergence of new storage technologies, system designers have found new uses for SRAM, such as: NetFlow (net flow), counters, statistics, packet buffering, queue management, and storage allocator.
Today, people's requirements for all routers and switches are not limited to FIB (forwarding information base) search. The counter needs to track the number of packets received for service and obtain statistical data to solve the billing problem. Continuously monitor the network (called NetFlow) through statistics to complete problem detection and determination. As the amount of processing per packet increases, packet buffers are needed to improve processing power. In addition to the above mentioned, as memory resources in the system increase, dynamic storage allocation is also necessary. All these additional functions of routers or switches are redefining the network system design (see Figure 1).
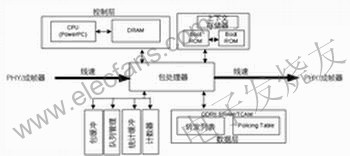
Figure 1 Network system with multiple new functions
In addition, with the rapid popularity of IPv6 and VRF (Virtual Router Forwarding), the demand for wider, deeper, faster and more efficient systems is becoming more urgent. The system designer must be able to meet all the metrics of the network system at the lowest cost. At this time, simple synchronous SRAM is difficult to meet the requirements. All of these functions can be implemented with faster and higher bandwidth SRAMs such as DDR (double data rate) or QDR (4 times data rate) SRAM. This article will analyze each of the above applications and their current and future requirements, and will also propose solutions and recommendations aimed at meeting these requirements.
QDR and DDR SRAM
The QDR Association, composed of Cypress, Renesas, IDT, NEC and Samsung, has developed QDR SRAM, which aims to meet those who need not only standard ZBT (zero bus turnaround time) or NoBL (no bus delay) SRAM's low latency and full-cycle utilization, and the need for bandwidth to significantly increase the operating frequency of the system. QDR SRAM has separate read and write ports, which operate independently of each other at double data rates on each data pin, thereby transmitting 4 data words in one clock cycle, and 4 times the data rate is so named. The use of separate read / write ports completely eliminates the possibility of bus contention between SRAM and the storage controller, which is a problem that traditional public I / O devices need to solve. QDRII SRAM has a source-synchronous clock called an echo clock, and they are generated together with the data output. QDR SRAM uses the HSTL (High Speed ​​Transceiver Logic) I / O standard for high-speed operation.
QDR SRAM is for applications that need to convert between read and write operations, while DDR SRAM is mainly for applications that require data streaming (for example, first perform 16 read operations and then perform 16 write operations). At this time, the near-term balance between read and write operations is 100% read operations or 100% write operations. In this case, a QDR SRAM bus is not used 50% of the time. Other buses may have unbalanced recent read / write ratios. The latter two cases are the main reasons for the development of DDR public I / O SRAM. In this device, the input and output data share the same bus. During the transition from a read operation to a write operation, a bus turnaround cycle is required, and the available bandwidth is reduced. However, for some systems, this will produce an average bus utilization that is superior to the QDR architecture. There are very few control signals, and they are slightly different from the QDR device control signals.
Internet application
As mentioned in the introduction, network system design involves many aspects. The number of various applications that are about to be implemented using network design is increasing. Discussed here are some of the most common applications.
Forwarding / routing
The Forwarding Information Base (FIB) is responsible for storing routing information used to determine the routing characteristics of incoming packets. The prefix representing the route can be stored in a ternary content addressable memory (TCAM) and searched instantly, or stored in SRAM and an algorithm is used to incrementally search several bits of the address. Regardless of the application, the resulting index has some associated information that indicates the action taken—the next hop address, update statistics, and replication on another port. The traditional approach is to store this information in SRAM.
Compared with the expandable and scalable package classification solution (in which TCAM is gradually becoming the de facto standard), a lot of research work has been done on the FIB algorithm. However, there are two development trends that pose major challenges to SRAM-based algorithms for FIB solutions: (1) With the increase in IPv6 support capabilities, the width of the entrance is also increasing; (2) Due to VRF tables and virtual private LAN services (VPLS) The adoption rate has increased, and the size of the routing table has grown larger and larger. As far as the VRF table is concerned, each VLAN stores a similar routing table, which increases the number of entries. VPLS is a new paradigm. With the help of it, the multi-layer network can be flattened to gain more entrances. As the entry width increases, SRAM-based algorithms need to build deeper and wider multi-branch / trie trees, which increases the number of SRAM accesses required to complete a search. As a result, more and more system designers have begun to use QDR SRAM to replace traditional SRAM, because the former provides higher bandwidth and can achieve a wider tree structure, because more can be completed within a specified time period Access.
NetFlow
Cisco Systems' NetFlow technology is a major component of Cisco IOS software, used to collect and measure data as it enters a specific router or switch interface. By analyzing NetFlow data, network engineers can discover the causes of congestion; determine the type of service (CoS) for each user and application, and confirm the source and target networks of traffic. NetFlow implements extremely detailed and accurate traffic measurement and advanced aggregate traffic collection functions.
Currently, the IETF (Internet Engineering Task Force) is standardizing the existing version of NetFlow (ver9) and naming it IPFIX. In addition to Cisco, network providers such as Enterasys and Juniper have played a role in the development of the standard and have expressed interest in adopting IPFIX. Of course, in a multi-model network, as a consistent source of network application flow related information, NetFlow / IPFIX is far more attractive than other solutions.
In summary, NetFlow provides the following information:
* Source IP address
* Destination IP address
* Source port
* Destination port
* Layer 3 protocol type
*Service type
NetFlow is only responsible for capturing inbound traffic, so it is usually necessary to install meters on both ends of the link. Currently, NetFlow is implemented using software that uses special algorithms and stores data in QDR SRAM. Because NetFlow is a new technology that needs to meet a certain line rate, it is implemented using QDR. Today, most suppliers of next-generation routers / switches that can achieve 40Gbps "56Gbps data rates are focusing on QDR SRAM with 250MHz" 300MHz operating speed. As the data rate increases, the speed index of SRAM becomes more and more important.
counter
In every network application, metrics need to be maintained at all times. Counters are necessary to track network activity. For each network protocol, a specific metric needs to be tracked. For example, at the IP layer (Layer 3), a datagram / second counter for displaying network traffic sent in the form of datagrams is usually set. These datagrams are generally broadcast packets, so in order to reduce broadcast traffic, it is necessary to understand which services and processes use datagrams. This information can be obtained through the datagram counter. In TCP (ie layer 4), a similar counter is the TCP segment / second counter, which provides the total number of TCP segments received and sent by the network. In addition, each network maintains an error counter for tracking the number of detected transmission errors and collisions. In general, the increase in the number of counters required for each network will be regarded as a manifestation of insufficient network buffer space.
statistics
In addition to NetFlow, some vendors also implement billing and diagnosis as statistics in a separate system. For example, in the service provider's network, billing forms a very important metric. Each customer's network usage records should be kept to obtain the customer's billing information. Statistics can be stored per data stream or per aggregation group. In the statistical buffer, delay and burst operation are important determinants for memory selection. During packet processing, fast access to statistical data is required, so low latency is critical. Moreover, because the number of digits in the statistical data is often not very large, SRAM with short burst operation or no burst operation should be preferred.
Similar to counters, in most customer systems, statistics are implemented with the help of similar mathematical algorithms and data stored in DDR SRAM. The requirements for all speed and storage density specifications of SRAM for counters also apply to statistical SRAM.
Packet buffer
Packet buffer memory is usually used to buffer the output port and the information packets in the switch structure during packet processing. In standard line cards, the packet processor has a packet buffer in which the contents of the packet will be stored while performing packet header processing. The determining factors in the packet buffer memory are the speed of the ASIC / NPU and the line rate. Slower ASICs require a buffer memory with a higher storage density. The buffer memory also depends on the type of service provided by the line card. If you are performing a more complex service, the ASIC usually requires more time to process the packet, so more buffering must be performed. The choice of ASIC design or NPU also determines other characteristics including burst operation and I / O width requirements. For some of these applications, latency is a crucial indicator. In such cases, a packet buffer with lower latency should be selected. Therefore, such designs usually use QDR or DDR SRAM (not DRAM) for packet buffering. However, some applications require a deeper packet buffer, and the ASIC needs to perform more operations. At this time, the most economical solution is to use DRAM to achieve this function. Therefore, in the process of implementing the packet buffer, there is always a trade-off. Currently, the design goals of line cards are to achieve higher speeds and process more packets. This means that the packet buffer processor should have both depth and speed. In response to this requirement, the implementation of QDR SRAM will be the ideal solution.
Queue management / traffic regularization
The queue manager is responsible for ensuring that the received packets comply with the communication contract. The work of the queue manager includes tagging the packet after comparing with the contract. Each line card interface has an input queue (input packets will be placed on the queue to wait for the routing processor to process) and an output queue (the routing processor will send the pending transmission on the interface The packet is placed on this queue). In some cases, customers can manage these queues by implementing counters (managing the flow of incoming packets based on processing power). Because this application requires speed more than density, and the read / write ratio is almost 1, QDR SRAM will be its ideal choice.
Dynamic memory allocation
On the line card, there are usually several sets of memory for different applications. This tends to increase the number of memory chips on the circuit board and the type of memory used in the same design. Today, designers use SRAM when they start implementing storage allocators to manage the available memory banks. The memory allocator SRAM is responsible for storing the address specifications of all memory groups, and provides access to a specific set of memory to the requesting application upon request. This allows designers to share the same set of memory chips between different applications without request conflicts. This application requires fast access to SRAM, and almost all read operations are more and write operations are less. Therefore, for this occasion, the most suitable choice is DDR SRAM.
Conclusion
New network applications have opened many doors for QDR and DDR SRAM to win design opportunities. Since the current generation of QDRII / DDRII SRAM with 300MHz (DDR) speed and 72Mb of data storage space can meet all the requirements of the next-generation 40Gbps "56Gbps router / switch, most network applications are slowly adopting QDR / DDR SRAM Transition. In addition, as these routers / switches reach the next node (80Gbps line rate) level, QDRII + / DDRII + and QDRIII / DDRIII SRAM can achieve higher speed and storage density. In addition to speed and storage density, QDRII + / DDRII + also has many features designed to achieve simple PCB and system design.
Portable Generator,Perkins Generator Set,Perkins Diesel Generator Set 120Kw,Perkins Diesel Generator Set 360Kw
Jiangsu Lingyu Generator CO.,LTD , https://www.lygenset.com